
Abstract
Existing learning-based dehazing algorithms struggle to deal with real world hazy images for lack of paired clean data. Moreover, most dehazing methods require significant computation and memory. To address the above problems, we propose a joint dual-teacher knowledge distillation and unsupervised fusion framework for single image dehazing in this paper. First, considering the complex degradation factors in real-world hazy images, two synthetic-to-real dehazing networks are explored to generate two preliminary dehazing results with the heterogeneous distillation strategy. Second, to get more qualified ground truth, an unsupervised adversarial fusion network is proposed to refine the preliminary outputs of teachers with unpaired clean images. In particular, the unpaired clean images are enhanced to deal with the dim artifacts. Furthermore, to alleviate the structure distortion in the unsupervised adversarial training, we constructed an intermediate image to constrain the output of the fusion network. Finally, considering the memory storage and computation overhead, an end-to-end lightweight student network is trained to learn the map** from the original hazy image to the output of the fusion network. Experimental results demonstrate that the proposed method achieves state-of-the-art performance on real-world hazy images in terms of no-reference image quality assessment and the parameters.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Images captured in hazy weather often have blurred edges, reduced contrast, and shifted color due to the scattering effect of floating practices in the environment. The obvious image degradation caused by haze can significantly affect the performance of computer vision systems, such as object detection [1,2,3], image segmentation [4], and classification [5]. Single image dehazing aims to recover the haze-free image from the degraded input. As a long-standing research problem in the vision community, it has attracted more and more attention in the computer vision and graphics community.
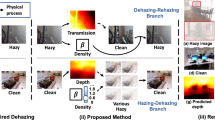
Mathematically, the haze process can be described with the physical scattering model, which is formulated as follows.
where \(X\left( \mu \right) \) and \(Y\left( \mu \right) \) indicate the hazy image and the corresponding haze-free version. \(T\left( \mu \right) \) and A denote the transmission map and the global atmosphere light. Specifically, the transmission map \(T\left( \mu \right) = {e^{ - \beta d\left( \mu \right) }}\) can be expressed with the depth map \(d\left( \mu \right) \) and the medium extinction coefficient \(\beta \) that reflects the haze density.
Given a hazy image X, recovering its haze-free version Y is a challenging ill-posed problem. Existing methods always estimate the transmission map \(T\left( \mu \right) \) and the global atmosphere light A with various priors, such as the color attenuation prior [6] and the dark channel prior [7]. Unfortunately, statistical priors do not always hold for hazy images of the real world, leading to limited performance in a complex practical scene [8]. Furthermore, these prior-based methods always suffer from nonconvex optimization problems with high computation overhead [9].
With the advent of deep neural networks [10], learning-based methods have achieved excellent performance. Supervised methods either utilize the neural network to estimate global air lights and transmission maps [11, 12], or generate clean images with the large-scale paired dataset [ Visual comparison of dehazing results for real-world haze images. Only sky regions of the proposed method are blue and visually pleasing
Compared with state-of-the-art dehazing methods, the proposed method can effectively recover haze-free images with vivid color. As shown in Fig. 1, only the sky regions of the proposed method are blue and visually pleasing. The contributions of the proposed method are summarized as follows:
-
We propose a joint dual-teacher distillation and unsupervised fusion framework for unpaired real-world hazy images. Considering that there are no ground truth for real-world hazy images, two synthetic-to-real dehazing networks are explored to generate two preliminary dehazed results with different distillation strategies.
-
We propose an unsupervised fusion scheme with a single generative adversarial network to refine preliminary dehazing results of two teachers. Unpaired clean images are enhanced to overcome the dim artifacts. Furthermore, to alleviate the structure distortion in the unsupervised adversarial training, we constructed an intermediate image to constrain the output of the fusion network.
-
Comprehensive experiments demonstrate that the proposed method achieves state-of-the-art performance on the real-world hazy images, in terms of no-reference image quality assessment and the parameters.
Related works
Prior-based methods
The classical dehazing algorithms mainly analyze the degradation mechanism of hazy images, and then estimate physical parameters such as transmission maps and atmospheric light based on certain image priors. The clear images are restored from estimated parameters and hazy images based on atmospheric scattering models. He et al. [7] proposed the famous dark channel prior by statistically analyzing the channel information of clear images, which meant that clear images have at least one channel with lower brightness except for the sky area. The dehazing algorithm with the dark channel prior can cause obvious color distortion and blocky defects in the sky area of the image. Many subsequent algorithms improved the dark channel prior algorithm from different aspects. Dai et al. [25] combined Retinex theory to optimize the atmospheric scattering model, and decomposed the clear images into a reflection map and a spatially varying illumination map. BorKar and Mukherjee et al. [26] applied the dark channel prior to the Y channel of the YCbCr color space and estimated the transmission map in the RGB color space. Finally, the brightness information of the dehazed image was adjusted to avoid the dim artifact in some regions. Although these methods improved the dehazed results to some extent, they sometimes led to obvious color distortion for the varicolored hazy images. In addition to the dark channel prior, many algorithms proposed different types of priors. Kaur et al. [27] first estimated the transmission map and atmospheric light based on the gradient channel prior and optimized the transmission map using L0-guided filtering. Although it partially corrected for the problem of color distortion, the hyper-parameter selection was quite cumbersome. To improve the efficiency, Liu et al. [28] proposed a rank one prior for the statistical analysis of images, which greatly improved the efficiency in practice. Ju et al. [29] proposed a region line prior based on the relationship between the corresponding regions of foggy images and clear images. Based on this novel prior, the dehazing task was transformed into a two-dimensional optimization function. This algorithm alleviated oversaturation to some extent in the dehazed results. Liu et al. [24] transformed the dehazing procedure into a task of improving image visibility and contrast. They performed contrast and low-light image enhancement to obtain two intermediate images and then fused the intermediate images to obtain the corresponding dehazed results. Although prior-based algorithms achieved good dehazed results, they sometimes led to obvious artifacts and some issues when priors were not held in realistic scenes.
Learning-based methods
Recently, deep learning-based algorithms have made great progress in many fields [30,31,32], which can be roughly categorized into three groups based on the characteristics of the datasets: supervised methods, semi-supervised methods, and unsupervised dehazing methods. Supervised dehazing methods mainly utilize paired hazy/clear images, transmission maps, and atmospheric light in the synthesized dataset to train the neural network. Some algorithms first used neural networks to estimate the corresponding parameters such as the transmission map and atmospheric light, and then haze-free images were recovered through atmospheric scattering models. Li et al. [33] proposed the first deep learning-based dehazing algorithm. To avoid the cumulative error of estimating the transmission map and atmospheric light parameters separately, many dehazing algorithms transformed the atmospheric scattering model, converted the parameters of the transmission map and atmospheric light into an intermediate variable, and then obtained the clear dehazing results with the transformed model. To further reduce errors caused by parameter estimation, more algorithms learned the map** of hazy images to clear images with improved network structures, loss functions and other aspects [\(Y_{en}\), which is the output of the unsupervised fusion network. The dehazed result Y is also constrained with the dark channel loss, which can mitigate the haze residue in the dehazing process.
Fusion and enhancement
In the unsupervised fusion network, two preliminary dehazing results \(Y_{1}\) and \(Y_{2}\) are mixed with the adversarial learning strategy. To avoid the structure distortion during the unsupervised adversarial training, the intermediate image \(Y_{3}\) is obtained with adaptive similarity maps according to the chrominance information and gradient modulus of the LMN color space [50]. To obtain the chrominance information, we first calculated the M and N channels from the RGB color space as follows.
Then, the similarity map according tho the the chrominance information is computed as:
where \(M_{1}\) and \(N_{1}\) stand for M and N channels of \(Y_{1}\), \(M_{2}\) and \(N_{2}\) related to M and N channels of \(Y_{2}\).
As for the similarity related to the gradient information can be calculated as follows:
We can calculate the overall similarity maps between the dehazed image and the original image as follows:
The weight maps of \(Y_{1}\) and \(Y_{2}\) can be calculated with the Softmax function, which defined as follows:
The image \(Y_{3}\) can be obtained by combining the preliminary dehazed results \(Y_{1}\) and \(Y_{2}\) with their weight maps as follows:
\(Y_{3}\) is used as an intermediate image to constrain the output of the unsupervised fusion network.
Network structure
To improve the generalization on the real-world hazy image, two synthetic-to-realistic dehazing networks RIDCP [22] and ENID [23] are selected as teachers. The RIDCP encoder consists of some residual layers and four down-sampling layers followed by four residual transformer blocks. As for the decoder, it has a symmetric structure with the encoder. Specifically, the deformable convolution is introduced to align different features. In addition, we adopt the multiscale boosted module dehazing network proposed in [23] as the second teacher, which consists of an encoder module, a boosted decoder module, and a dense feature fusion module. Different from the original architecture proposed in [13], the proposed encoder module contains dual learning branches with different parameters to deal with the distribution discrepancy between the synthetic hazy dataset and the realistic dataset. The Strengthen-Operate-Subtract strengthening strategy [13] is incorporated into the decoder to recover haze-free images. To remedy the missing spatial information caused by the down-sampling operation in U-Net, the dense feature fusion module exploits features from nonadjacent levels with the back-projection technique.
To generate a more visually pleasing result, we adopt a U-Net generator as the fusion network to fuse \(Y_{1}\) and \(Y_{2}\) with the adversarial learning strategy [51]. The original clean image Z is enhanced with CPAHE [24] to improve image quality and overcome the dim artifact. The global discriminator and the local discriminator try to discern whether the fused result \(Y_{en}\) is similar to the enhanced images \(Z_{en}\).
Unlike the teachers, a lightweight dehazing network with an effective feature attention block is proposed as the student. The student first employs one regular convolutional layer and four down-sampling operations to quarter the input hazy image in side length. Each down-sampling module contains one 3*3 convolution layer with stride 1 and two convolution layers with stride 2 following a ReLU per layer. The down-sampled features are fed to one attention module in the bottleneck layer, and then four upsampling modules and one regular convolution layer are employed to restore the haze-free image. Furthermore, instead of the common skip connection with concatenation or addition, the adaptive mixup fusion strategy [52] is introduced in the student to exchange information between the shallow features and high-level features.

The overall architecture of the proposed joint fusion and dual teachers knowledge distillation framework. Only the lightweight student is used in test
To enhance the feature extraction ability, we also introduce the attention mechanism in the bottleneck layer of the student. As shown in Fig. 3, the feature maps \(F_{in}\) in the low-resolution space are grouped with horizontal kernels and vertical kernels inspired by coordinate attention [53]. To promote information exchange between channels, the channels of the pooled feature maps \(F_{h}\) and \(F_{v}\) are squeezed from C to C/r, then \(F_{h}\) and \(F_{v}\) perform element-wise product operation to embed position information. Finally, the channels are changed to C with a Conv-Shuffle-Sigmoid block, and the feature map \(F_{out}\) can be generated with the attention map to emphasize the regions of interest.
Loss function
In the proposed framework, all the parameters of two teachers are fixed. The GAN-based unsupervised fusion network and the student are updated with different loss functions in the training process.
Loss function for the fusion network. Inspired by the unsupervised image-to-image translation, a U-Net is applied as a generator to fuse initial dehazed images of two teachers into the refined result with adversarial loss and structure-preserving loss. The loss function for the GAN-based unsupervised fusion network is defined as follows:
where \(L_{adv}\) stands for the adversarial losses, \(Y_{en}\) and \(Z_{en}\) relate to examples sampled from the output distribution \(P_{fake}\) and haze-free distributions \(P_{real}\). \(L_{adv}\) is employed to make the output results similar to the haze-free images.
In addition to the adversarial loss, the perceptual loss function \(L_{vgg}\) is also utilized to preserve the structure of the fused result. The perceptual loss with the pre-trained VGG19 network is defined as follows:
where \(\varphi _{i,j}(\cdot )\) represents the feature maps of the pre-trained VGG19 network.
In addition, a global discriminator \(D_{G}\) and a local discriminator \(D_{L}\) are also used to discern the outputs \(Y_{en}\) and \(Z_{en}\) in the unsupervised adversarial training process. The loss functions for discriminators are defined as follows:
where \(Z_{en-patches}\) and \(Y_{en-patches}\) used in the training of local discriminator stand for patches randomly sampled from the \(Z_{en}\) and \(Y_{en}\).
Through adversarial training, the output \(Y_{en}\) of the fusion network is similar to the high-quality image \(Z_{en}\). We then adopt \(Y_{en}\) as the corresponding haze-free image to train the student with the input of the original hazy image X.
Loss function for the student. The full loss function \(L_{s}\) for the student is formulated as:
where \(L_{pix}\) stands for the reconstruction loss, \(L_{per}\) relates to the perceptual loss with the VGG19 networks, \(L_{dcp}\) stands for the dark channel loss, and the \(L_{tv}\) is the TV (total variation) loss.
To recover the haze-free image, the mean absolute error is adopted to ensure the result Y close to the refined result \(Y_{en}\). The pixel loss is defined as:
where N stands for the number of hazy images, Y and \(Y_{en}\) represent the dehazing results of the student and the refined result.
The perceptual loss is explored with the pre-trained VGG19 network, which is defined as follows:
where \({\varphi _{i,j}}(Y)\) and \({\varphi _{i,j}}(Y_{en})\) stand for the feature maps of Y and \(Y_{en}\) in VGG19 network.
In addition to the pixel loss and the perceptual loss, the unsupervised dark channel loss and the total variation losses are also adopted to ensure that the recovered images have the characteristics of the clean images. Dark channel prior is widely used in the image dehazing task. Inspired by the dark channel prior, the dark channel loss is defined as:

where y represents the coordinate of image patch Q, and \(Y^{c}(y)\) relates one color channel of the dehazed image Y.
To preserve the sharp structure of the dehazed result Y, the total variation loss \(L_{tv}\) is also utilized with an L1 regularization gradient prior, which is expressed by:
where \(\nabla _h\) represents the horizontal differential operation matric, \(\nabla _v\) stands for the vertical differential operation matric.
Experiments
Datasets and implementation details
We choose the Unannotated Real Hazy Images (URHI) subset from the Realistic Single Image Dehazing (RESIDE) dataset [17] as the real-world hazy images in training the student. URHI subset consists of 4807 real-world hazy images without ground truth. All images are crawled from the Internet with different haze density, covering complex scenarios and including various degradation factors, such as poor light condition. Furthermore, 3577 unpaired clear images in RefinedDet [50] are adopted as the haze-free domain in training the unsupervised GAN-based fusion network. RTTS subset is adopted as the test dataset to evaluate the dehazing performance of different dehazing methods. RTTS consists of 4322 unpaired real-world hazy images, which are annotated with 41,203 bounding boxes and five object categories.
All parameters of the teacher networks are fixed during the training process. The GAN-based fusion network is first trained 100 epochs with a learning rate of 1e-4. The learning rate is linearly decayed to 0 in the following 100 epochs. The student network is trained 120 epochs with Adam optimizer and a batch size of 32. The initial learning rate 1e-4 decays every 45 epochs with a rate of 0.75 until 5e-5. The loss weights are set as \(\lambda _{vgg}=1\), \(\lambda _{pix}=10\), \(\lambda _{per}=1\), \(\lambda _{dcp}=1\) and \(\lambda _{tv}=0.0001\). We carry out experiments with the PyTorch framework on two GEFORCE RTX 3090.
Comparison with state-of-the-art methods
We compared the proposed method with eight state-of-the-art dehazing methods quantitatively and qualitatively. Among these methods, the traditional method DCP [7] proposed the famous dark channel prior to recover the haze-free images. the supervised method [13] made great dehazing performance for the well-designed network structure. The semi-supervised methods are SSID [9], DAD [8], RIDCP [22] and ENID [23]. The zero-shot dehazing method YOLY [42] only needs one hazy image in the training stage. The unsupervised dehazing method D4 [19] tried to improve the dehazing performance with the generative adversarial network. Quantitative and qualitative experiments are conducted on the real hazy images, including visual quality, no-reference image quality evaluation, task-driven evaluation, and model complexity.

Visual comparison on the real-world hazy images
Visual Quality. We perform visual quality comparison on the widely used RTTS dataset, which crawled 4,322 real-world hazy images from the Internet, covering diverse haze densities with complex degradations in outdoor environments. The dehazed results of the prior-based method DCP, the supervised method MSBDN; the semi-supervised methods SSID, DAD, RIDCP and ENID, the unsupervised methods YOLY, D4, and the proposed method are shown in Fig. 4. It can be observed that the classical prior-based method DCP suffers from obvious color distortion, such as the purple sky in the first example. The main reason is that the dark channel prior is not suitable in the sky area. Similarly, the YOLY also suffers from the color distortion issue. Although MSBDN, SSID, DAD, and D4 can deal with color distortion well, the distant regions in the dehazed images seem a little different from the original hazy images due to the dense fog, for example, the distant building in the first example. Recently, RIDCP and ENID improve the generalization on real-world hazy images, but there are still obvious haze residues in the dehazed results, such as the building in the first example and the trees in the second example. Especially, all the former-mentioned approaches cannot deal well with the sky area with dense haze, the sky regions in the recovered images are still hazy. In comparison, the proposed method can generate visually pleasing and clean results in terms of less haze residue, sharper edges, and brighter details.

Visual comparison on the real-world hazy images in dim scenes
Furthermore, most existing approaches cannot overcome dim artifacts in the dehazing process because of the duality between image dehazing and low-light image enhancement. The detailed information in the near region is lost in the dehazed results, such as the roads in Fig. 5. Although RIDCP and ENID can alleviate this problem to some extent, they cannot recover the details in low light regions, such as the trees in the second example of Fig. 5. Compared to existing methods, the proposed dehazing algorithm can generate the best perceptual haze-free images with high-quality details.
No-Reference Image Quality Assessment. Since there are no ground truths for the real world hazy images, the widely used fog-aware density assessor (FADE) index [54] is adopted as the metric of non-reference image quality assessment in the experiment. The lower value of the FADE index indicates better dehazing performance. Quantitative comparisons of dehazed results on the RTTS dataset are illustrated in Table 1. It can be seen that the proposed method achieves the best performance 0.590 in terms of the FADE index. Compared to the original value of 2.484, the proposed method achieves the gains with 73.8%. Especially, it outperforms the two teachers RIDCP and ENID approximately 37.5% and 9.2%, respectively.
Task-Driven Evaluation. Hazy images always suffer from blurred edges, reduced contrast, and limited visibility, which may severely deteriorate the performance of high-level vision tasks, such as object detection. Single image dehazing is often utilized as a pre-processing step to improve the detection accuracy. We compared the mean Average Precision (mAP) of different dehazing results with the YOLO [55] on the RTTS dataset, which are annotated with five classes and bounding boxes. All 4322 real-world hazy images are recovered before the detection task. As shown in Table 2, the proposed method comes second in the mAP index, and improves the value from 63.32 to 65.23, which further demonstrates that the proposed method can generate cleaner results and sharper structures.
The comparison on the parameters of the methods. In addition, it also outperforms the two complex teachers with a lightweight structure. As shown in Table 3, it can further reduce the parameters from 29.5 M and 31.4 M to 6.5 M. In total, the best dehazing performance and the least parameters demonstrate the superiority of the proposed method.

Visual comparison on the real-world hazy images with different components
Ablation study
Effectiveness of different components. To evaluate the effectiveness of different components, a series of ablation experiments are conducted as follows. (1) W/O ENID: the teacher ENID is not adopted in the training process. (2) W/O RIDCP: the teacher RIDCP is not utilized in the training process. (3) W/O pre_en: the hazy images without enhancement are directly fed to the RIDCP dehazing network. (4) W / O GAN: The general adversarial network is not used to fuse the results of the two teachers. (5) W/O DCP: the dark channel loss is removed. (5) Ours. The dehazing results of algorithms with different components are shown in Fig. 6. It can be observed that the proposed method can generate the most visually pleasing result compared to the other methods, such as the tree area in the red box of the first example and the sky region in the green box of the second example. In Fig. 6b, c, dehazing methods without ENID or RIDCP may result in some haze residue in distant areas. In Fig. 6d, f, dehazing methods without the pre_en or DCP loss may cause lower contrast of the restored images. In particular, if adversarial training is removed in the second stage, the grass area and the sky region in the green box in Fig. 6e cannot be well recovered. Compared to other methods, the proposed method can generate visually pleasing results, which demonstrates the effectiveness of different components.
Impact and selection of hyperparameters \(\lambda _{vgg}\) and \(\lambda _{dcp}\). With the adversarial training strategy, an unsupervised fusion network used as generator is proposed to make the fused results similar to the unpaired clean images. In addition to adversarial loss, vgg loss with weight \(\lambda _{vgg}\) is introduced with the preliminary fused results \(Y_{3}\). The value of the hyperparameters \(\lambda _{vgg}\) and the fused results are shown in Fig. 7. It can be observed that the outputs of the fusion network are almost the same as \(Y_{3}\) when \(\lambda _{vgg} >=2\). The main reason is that large values of the weight \(\lambda _{vgg}\) tend to result in the model collapse in the adversarial training.

Impact of the hyperparameter \(\lambda _{vgg}\)
\(\lambda _{dcp}\) in existing algorithms is often set as a small value, for example, \({10}^{-5}\) in SSID [9], \({10}^{-3}\) in PSD [9]. In the proposed method, the \(\lambda _{dcp}\) is set to 1 in the training of the student network. We retrain the student network by varing hyperparameters \(\lambda _{dcp}\) while fixing the others. The loss curves with different \(\lambda _{dcp}\) are shown in Fig. 8. It can be observed that the dark channel loss can converge well when \(\lambda _{dcp} =1\).

Selection of the hyperparameter \(\lambda _{dcp}\)

Visual comparison with different teachers
Effectiveness of different teachers. To verify the effectiveness of the proposed framework, two other dehazing networks PSD [22] and FFANet [34] are selected as new teachers to replace RIDCP [22] and ENID [22]. The dehazing results of the algorithms with different teachers are shown in Fig. 9. It can be observed that the proposed method generates clean results in terms of less haze residue, for example, in the distant trees in the first example and the building area in the green box of the second example. In Fig. 9b, the dehazed framework with PSD and FFANet as teachers suffers from severe haze residues; the main reason is that FFANet trained with the synthetic dataset cannot generalize well in the real scenes due to the domain shift. Although the synthetic-to-realistic dehazing method PSD improves the performance on the real-world hazy images, it tends to cause color distortion in some regions of the dehazed results, such as the regions in the red box of the second example. Compared to existing methods, the proposed dehazing algorithm can generate the best perceptual haze-free images with high-quality details.
Conclusion
In this paper, we propose a joint dual-teacher distillation and unsupervised fusion framework for unpaired real-world hazy images. An unsupervised fusion scheme for the dehazing results of two teachers is proposed with the generative adversarial network to assist the student in training. Specially, the unpaired clean images are further enhanced to overcome the dim artifacts that occurred in the dehazing task. We conduct comprehensive experiments to verify the superiority of the proposed method in terms of no-reference image quality assessment and the parameters. In the future, we will explore the unsupervised domain adaptation and the depth map to deal with dense haze removal, especially in the distant region.
