
Abstract
Consolidating published research on aluminum alloys into insights about microstructure–property relationships can simplify and reduce the costs involved in alloy design. One critical design consideration for many heat-treatable alloys deriving superior properties from precipitation are phases as key microstructure constituents because they can have a decisive impact on the engineering properties of alloys. Here, we present a computational framework for high-throughput extraction of phases and their impact on properties from scientific papers. Our framework includes transformer-based and large language models to identify sentences with phase-property information in papers, recognize phase and property entities, and extract phase-property relationships and their “sentiment.” We demonstrate the application of our framework on aluminum alloys, for which we build a database of 7,675 phase–property relationships extracted from a corpus of almost 5000 full-text papers. We comment on the extracted relationships based on common metallurgical knowledge.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Global demand for metals is expected to increase two to sixfold by 2100 [1,2,3]. This is especially true for aluminum as there is a growing demand for high-performance, lightweight, recyclable structural alloys across industries [4, 5]. In the context of recycling, shifts in end-uses lead to uncertainties in the future scrap stream compositions, which is further exacerbated by accumulation of detrimental elements as alloys are recycled [6]. For example, increasing recycling content often leads to the emergence of phases (e.g., iron-containing intermetallics) detrimental to mechanical and other properties [7, 8].
Understanding microstructure–property relationships is the foundation for any alloy design effort (including recyclability considerations). Microstructure constituents of special interest in aluminum alloys are phases—spatial regions of uniform crystal structure and chemistry. Many beneficial properties are achieved based on the formation of desirable phases, for example, in the form of fine precipitates [9]. Conversely, many performance characteristics sharply deteriorate in the presence of phases with undesirable size or morphology. Given the importance of phases as key microstructure constituents, a large body of work has been dedicated to experimental observation of phase formation in response to metallurgical processing. Systematically organizing the knowledge published in the literature over decades of research could greatly benefit the current alloy design endeavors.
In recent years, natural language processing (NLP) has emerged as a powerful tool for analysis of large sets of scientific texts. It has been applied to the design and discovery of battery materials [10], complex oxides [11], zeolites [12, 13], nanoparticles [14], and more [15, 16]. However, development and application of NLP to the design of structural alloys are still in early stages. Sample research includes the text-mining of millions of papers to efficiently design high-entropy alloys [17] as well as predicting the pitting potential for corrosion-resistant alloy design using embeddings of literature excerpts [18]. Relevant to aluminum, Liu et al. have created a labeled dataset of material entities from the literature focused on the Al-Si alloy system [19]. Their use of active learning to supplement their manual labeling of entities, however, highlights the need for an automated high-throughput extraction method applicable to different regions of the alloy space. On the other hand, Pfeiffer et al. considered the entire range of aluminum alloy series and extracted 14,884 aluminum alloy compositions, along with 1,278 properties from 5,172 research papers [20]. While covering wide independent ranges and distributions of engineering properties, their database does not contain links between compositions and properties.
To address this gap, we develop an NLP framework to automatically extract, from the literature, phases, and their "sentiment" in terms of positive or negative impact on properties. We leverage large language models (LLMs) to perform a wide variety of NLP tasks (including named entity recognition (NER) and relationship extraction (RE)), without the need for extensive manually labeled datasets [21]. By performing automated collection of relevant sentences, NER, and relationship inference using transformer-based models and LLMs, we create a database of existing phase–property relationships. We demonstrate the uses of this database for gaining insights that we confirm against established metallurgical knowledge. We focus on aluminum alloys, but the framework presented here is flexible and can be applied to other metallic systems. We develop the framework in Sect. 2 and show how it can derive key insights from the aluminum system in Sect. 3. The framework’s uses and implications for researchers will be discussed in Sect. 4.
NLP Framework for High-Throughput Extraction of Phase–Property Relationships
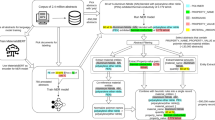
In this section, we present an NLP framework for extraction of phase–property relationships in alloys from the literature applied to aluminum alloys. We (i) collect a corpus of relevant papers, (ii) extract sentences from full-body papers, (iii) perform NER and extract phase–property relationships, (iv) aggregate or disambiguate the extracted entities (Fig. 1).

Summary of our NLP framework
Paper Corpus Collection
We first build a corpus of papers related to aluminum alloys culled from our in-house database of more than 5.7 million full texts of papers published in academic journals [22]. Our search for relevant papers included two strategies: (i) rule-based regular expression (regex) matching of words in titles and abstracts of the in-house database and (ii) querying the Scopus database [23]. In the first search strategy, we used the following five rules, which checked the presence of:
-
The words alumin(i)um and alloy in the title,
-
Alloy denominations in the title, (ex: "Al6061"),
-
Alloy series in the title (ex: "7xxx", "6xxx"),
-
Alloy names using chemical elements (ex: "Al-Si", "Al-Mg-Sc-Zr") along with the word alloy in the title,
-
Alloy numbers consisting of 3 or 4 consecutive numbers (ex: "5182", "A382") with a mention of alumin(i)um in the title or abstract.
A paper satisfying any of those rules was considered an aluminum text. We found a total of 19,356 articles in our database of full texts. To complement this search, we also queried the Scopus database for papers on the subject of aluminum alloys. We queried papers that contained strings "alumin*um" or "Al-" and "alloy" in the titles but excluded those having "-Al" to remove papers with aluminum as an alloying element. The Scopus queries provided a further 1,164 articles that that were not already present in the list of relevant papers identified with the regex search. Having the combined list of articles on aluminum alloys, we downloaded full texts of these articles from our in-house database to obtain a final corpus of 20,520 full texts in the JSON format.
Sentence Dataset Collection
From the paper corpus, we then extract the sentences that contain information on phases and properties to build a sentence dataset. We choose the sentence as the main unit of text because papers in metallurgic literature often discuss multiple phases and properties in a single paper. Focusing on a smaller unit of text reduces the possibilities of ambiguous relationships. On the other hand considering larger units of text (e.g., paragraph) may challenge extraction of unambiguously coupled phase–property pairs and the sentiment of their relationships. Furthermore, we hypothesize that the description of phases and their impact on properties is captured at the sentence level in the metallurgical literature at a sufficient level for insights to be gathered. Finally, focus on a small unit of text enables use of a wide spectrum of NLP tools and LLMs, including those with limited context windows.
The prototypical sentence that we targeted to include in the sentence dataset reads as "[Phase A] leads to an increase in [property B]". Such sentence extraction can be approached as a classification problem, i.e., whether or not a given sentence contains the phase-property information, or whether or not it resembles our prototypical sentence. Here, we chose BERT-type transformer models coupled with a classification head to perform this task. For best performance, we fine-tuned and evaluated four BERT models: the uncased versions of the original BERT [52], which in turn can form a foundation for interactive systems of fast and user-friendly retrieval of materials information. Our sentence dataset can be utilized as information-dense source of text data that can be used as domain-specific context for conversational LLMs (e.g., for retrieval-augmented generation [53]).
We finally note the key role of LLMs in building our framework without the need in excessive amounts of manually labeled data. Specifically, we observed a remarkable performance of LLMs in NER and RE tasks using only a handful of labeled examples (Sect. 2.3). The manual annotation of sentences for NER and RE tasks with more traditional NLP approaches would have been extremely time consuming. Furthermore, using few-shot learning, we could significantly improve the model performance without expensive fine-tuning. The sentence classification was addressed by fine-tuning BERT-type models, for which constituting a manually annotated dataset requires significantly less effort than NER and RE tasks.
Limitations and Future Opportunities
In this work, we developed a framework for high-throughput extraction of phases, properties, and their relationships from published literature on aluminum alloys. Ideally the framework should be fully automated, however, in the current state, some (semi-)manual intervention was still needed, most notably the aggregation of alias notations of the same phases/properties and their verification. For example, 15% of the extracted samples of the property "strength" have been aliased from otherwise worded terms referring to strength. Similarly, our database contains the property "corrosion," which aggregates not only the term "corrosion" itself but also other related terms that constituted 79% of the final aggregated "corrosion" samples. We expect that rapid progress in NLP and LLMs will eliminate the need in these additional steps and allow extraction of one-to-one relationships of unique phases and properties.
This study focused on qualitative relationships between phases and properties, i.e., whether any given phase has a positive or negative impact on a property. Next efforts in this direction can pursue quantitative relationships as well as additional extraction of alloy chemical composition to further aid computational alloy design.
Finally, Fig. 5 shows that relationships described in literature are about 70–80% positive. This indicates a clear bias towards reporting "positive results," e.g., phases and phenomena that are beneficial to alloys properties. This bias results in unbalanced extracted datasets regardless how good the NLP framework for extraction is. The computational alloy design leveraging state-of-the-art NLP could benefit from a more balanced reporting of both negative and positive research results from the community.
Conclusion
In summary, we present a novel methodology for extracting phase–property relationships from metallurgic literature using natural language processing and large language models. The study focuses on the aluminum system and leverages the power of NLP and LLMs to systematically organize knowledge from a vast corpus of research papers. The insights generated from the extracted database show its use as a valuable guide for alloy designers and researchers seeking to optimize alloy performance.
The results presented here show that this framework is useful for rapidly extracting insights from literature on alloys. The knowledge we have derived on the aluminum system would, traditionally, be held in textbooks that would have taken years to write by experts. As research on alloy properties continues to grow, these tools will become an indispensable to quickly screen literature and gain insights.
Code Availability
The code and database are openly available on GitHub at the following address: https://github.com/olivettigroup/phase-sentiment.
References
Saevarsdottir G, Kvande H, Welch B (2019) Aluminum production in the times of climate change: the global challenge to reduce the carbon footprint and prevent carbon leakage. JOM 11:72. https://doi.org/10.1007/s11837-019-03918-6
Cullen JM, Allwood JM (2013) Map** the global flow of aluminum: from liquid aluminum to end-use goods. Environ Sci Technol 47(7):3057–3064. https://doi.org/10.1021/es304256s
Watari T, Nansai K, Nakajima K (2021) Major metals demand, supply, and environmental impacts to 2100: a critical review. Resour Conserv Recycl 164:105107. https://doi.org/10.1016/j.resconrec.2020.105107
Raabe D, Ponge D, Uggowitzer PJ, Roscher M, Paolantonio M, Liu C et al (2022) Making sustainable aluminum by recycling scrap: the science of “dirty’’ alloys. Prog Mater Sci 128:100947. https://doi.org/10.1016/j.pmatsci.2022.100947
Raabe D, Tasan C, Olivetti E (2019) Strategies for improving the sustainability of structural metals. Nature 11(575):64–74. https://doi.org/10.1038/s41586-019-1702-5
Gaustad G, Olivetti E, Kirchain R (2011) Toward sustainable material usage: evaluating the importance of market motivated agency in modeling material flows. Environ Sci Technol 45(9):4110–4117. https://doi.org/10.1021/es103508u
Yang H, Ji S, Fan Z (2015) Effect of heat treatment and Fe content on the microstructure and mechanical properties of die-cast Al–Si–Cu alloys. Mater Des 85:823–832. https://doi.org/10.1016/j.matdes.2015.07.074
Basak C, Hari Babu N (2017) Improved recyclability of cast al-alloys by engineering \(\beta \)-Al9Fe2Si2 phase. In: Light metals. Springer, pp 1139–1147
Wang J (2018) Physical metallurgy of aluminum alloys. In: Aluminum science and technology. ASM International. https://doi.org/10.31399/asm.hb.v02a.a0006503
Huang S, Cole J (2020) A database of battery materials auto-generated using ChemDataExtractor. Sci Data 08:7. https://doi.org/10.1038/s41597-020-00602-2
Young SR, Maksov A, Ziatdinov M, Cao Y, Burch M, Balachandran J et al (2018) Data mining for better material synthesis: the case of pulsed laser deposition of complex oxides. J Appl Phys 123(11):115303. https://doi.org/10.1063/1.5009942
Schwalbe-Koda D, Kwon S, Paris C, Bello-Jurado E, Jensen Z, Olivetti E et al (2021) A priori control of zeolite phase competition and intergrowth with high-throughput simulations. Science 374(6565):308–315. https://doi.org/10.1126/science.abh3350
Jensen Z, Kwon S, Schwalbe-Koda D, Paris C, Gómez-Bombarelli R, Román-Leshkov Y et al (2021) Discovering relationships between OSDAs and zeolites through data mining and generative neural networks. ACS Cent Sci 7(5):858–867. https://doi.org/10.1021/acscentsci.1c00024
Cruse K, Trewartha A, Lee S, Wang Z, Huo H, He T et al (2022) Text-mined dataset of gold nanoparticle synthesis procedures, morphologies, and size entities. Sci Data 05(9):234. https://doi.org/10.1038/s41597-022-01321-6
Tshitoyan V, Dagdelen J, Weston L, Dunn A, Rong Z, Kononova O et al (2019) Unsupervised word embeddings capture latent knowledge from materials science literature. Nature 571(7763):95–98. https://doi.org/10.1038/s41586-019-1335-8
Lee J, Lee M, Min K (2023) Natural language processing techniques for advancing materials discovery: a short review. Int J Precis Eng Manufact Green Technol 06:10. https://doi.org/10.1007/s40684-023-00523-6
Pei Z, Yin J, Liaw PK, Raabe D (2023) Toward the design of ultrahigh-entropy alloys via mining six million texts. Nat Commun. https://doi.org/10.1038/s41467-022-35766-5
Sasidhar KN, Siboni NH, Mianroodi JR, Rohwerder M, Neugebauer J, Raabe D (2023) Enhancing corrosion-resistant alloy design through natural language processing and deep learning. Sci Adv 9(32):eadg7992. https://doi.org/10.1126/sciadv.adg7992
Liu Y, Yao C, Niu C, Li W, Yin J, Shen T (2021) Text mining of hypereutectic Al–Si alloys literature based on active learning. Mater Today Commun 26:102032. https://doi.org/10.1016/j.mtcomm.2021.102032
Pfeiffer O, Liu H, Montanelli L, Latypov M, Sen F, Hegadekatte V et al (2022) Aluminum alloy compositions and properties extracted from a corpus of scientific manuscripts and US patents. Sci Data 03(9):128. https://doi.org/10.1038/s41597-022-01215-7
Dunn A, Dagdelen J, Walker N, Lee S, Rosen AS, Ceder G, et al (2022) Structured information extraction from complex scientific text with fine-tuned large language models. ar**v:2212.05238
Kim E, Huang K, Tomala A, Matthews S, Strubell E, Saunders A et al (2017) Machine-learned and codified synthesis parameters of oxide materials. Sci Data 4:sdata2017127. https://doi.org/10.1038/sdata.2017.127
Boyle F, Sherman D (2006) Scopus\(^{\rm TM}\): the product and its development. Ser Libr 49(3):147–153. https://doi.org/10.1300/J123v49n03_12
Devlin J, Chang MW, Lee K, Toutanova K (2018) Bert: pre-training of deep bidirectional transformers for language understanding. ar**v:1810.04805
Beltagy I, Lo K, Cohan A (2019) SciBERT: a pretrained language model for scientific text. ar**v:1903.10676
Trewartha A, Walker N, Huo H, Lee S, Cruse K, Dagdelen J et al (2022) Quantifying the advantage of domain-specific pre-training on named entity recognition tasks in materials science. Patterns 3(4):100488. https://doi.org/10.1016/j.patter.2022.100488
Gupta T, Zaki M, Krishnan NMA, Mausam M (2022) MatSciBERT: a materials domain language model for text mining and information extraction. NPJ Comput. Mater. 12:8. https://doi.org/10.1038/s41524-022-00784-w
Cohere LLM API. Accessed 30 Sept 2023. https://cohere.com/
Liang P, Bommasani R, Lee T, Tsipras D, Soylu D, Yasunaga M, et al (2022) Holistic evaluation of language models. ar**v:2211.09110
Lin CY (2004) Rouge: A package for automatic evaluation of summaries. In: Text summarization branches out, pp 74–81
Grootendorst M (2022) BERTopic: neural topic modeling with a class-based TF-IDF procedure. ar**v:2203.05794
Mrówka G (2010) Influence of chemical composition variation and heat treatment on microstructure and mechanical properties of 6xxx alloys. Arch Mater Sci Eng 12:46
Usta M, Glicksman M, Wright R (2004) The effect of heat treatment on Mg2Si coarsening in aluminum 6105 alloy. Metall Mater Trans A 02(35):435–438. https://doi.org/10.1007/s11661-004-0354-7
Jawalkar C, Verma AS, Suri N et al (2017) Fabrication of aluminium metal matrix composites with particulate reinforcement: a review. Mater Today Proc 4(2):2927–2936. https://doi.org/10.1016/j.matpr.2017.02.174
Arunkumar S, Sundaram MS, Vigneshwara S et al (2020) A review on aluminium matrix composite with various reinforcement particles and their behaviour. Mater Today Proc 33:484–490. https://doi.org/10.1016/j.matpr.2020.05.053
Wang X, Jha A, Brydson R (2004) In situ fabrication of \({\rm Al}_3{\rm Ti}\) particle reinforced aluminium alloy metal-matrix composites. Mater Sci Eng, A 364(1–2):339–345. https://doi.org/10.1016/j.msea.2003.08.049
Menzemer C, Lam PC, Srivatsan TS, Wittel CF (1999) An investigation of fusion zone microstructures of welded aluminum alloy joints. Mater Lett 41(4):192–197. https://doi.org/10.1016/S0167-577X(99)00129-9
Myhr OR, Grong Ø, Fjær HG, Marioara CD (2004) Modelling of the microstructure and strength evolution in Al–Mg–Si alloys during multistage thermal processing. Acta Mater 52(17):4997–5008. https://doi.org/10.1016/j.actamat.2004.07.002
Robles Hernández FC, Sokolowski JH (2006) Comparison among chemical and electromagnetic stirring and vibration melt treatments for Al-Si hypereutectic alloys. J Alloy Compd 426(1):205–212. https://doi.org/10.1016/j.jallcom.2006.09.039
Dash SS, Chen D (2023) A review on processing–microstructure–property relationships of Al–Si alloys: recent advances in deformation behavior. Metals. https://doi.org/10.3390/met13030609
Kim JC, Nishida Y, Arima H, Ando T (2003) Microstructure of Al-Si-Mg alloy processed by rotary-die equal channel angular pressing. Mater Lett 57(11):1689–1695. https://doi.org/10.1016/S0167-577X(02)01053-4
Natori K, Utsunomiya H, Tanaka T (2017) Improvement in formability of semi-solid cast hypoeutectic Al-Si alloys by equal-channel angular pressing. J Mater Process Technol 240:240–248. https://doi.org/10.1016/j.jmatprotec.2016.09.022
Al-Qutub AM, Allam IM, Qureshi TW (2006) Effect of sub-micron Al2O3 concentration on dry wear properties of 6061 aluminum based composite. J Mater Process Technol 172(3):327–331. https://doi.org/10.1016/j.jmatprotec.2005.10.022
Mahdavi S, Akhlaghi F (2011) Effect of SiC content on the processing, compaction behavior, and properties of Al6061/SiC/Gr hybrid composites. J Mater Sci 03(46):1502–1511. https://doi.org/10.1007/s10853-010-4954-x
Yu H, Huang X, Lei F, Tan X, Han Y (2013) Preparation and electrochemical properties of Cr(III)-Ti-based coatings on 6063 Al alloy. Surf Coat Technol 03(218):137–141. https://doi.org/10.1016/j.surfcoat.2012.12.042
Chong Z, Yang X, Wang Y, Zhang DQ, Chen Y (2019) Synergistic effect between glutamic acid and rare earth cerium (III) as corrosion inhibitors on AA5052 aluminum alloy in neutral chloride medium. Ionics 03:25. https://doi.org/10.1007/s11581-018-2605-4
Li T, Li X, Dong C, Cheng Y (2010) Characterization of atmospheric corrosion of 2A12 aluminum alloy in tropical marine environment. J Mater Eng Perform 06(19):591–598. https://doi.org/10.1007/s11665-009-9506-7
Ghosh R, Venugopal A, Rao S, Narayanan P, Pant B, Cherian RM (2018) Effect of temper condition on the corrosion and fatigue performance of AA2219 aluminum alloy. J Mater Eng Perform 01(27):423–433. https://doi.org/10.1007/s11665-018-3125-0
Osório WR, Spinelli JE, Ferreira IL, Garcia A (2007) The roles of macrosegregation and of dendritic array spacings on the electrochemical behavior of an Al-4.5wt% Cu alloy. Electrochimica Acta. 52(9):3265–3273. https://doi.org/10.1016/j.electacta.2006.10.004
Ma J, Wen J, Li Q, Zhang Q (2013) Electrochemical polarization and corrosion behavior of Al–Zn–In based alloy in acidity and alkalinity solutions. Int J Hydrogen Energy 38(34):14896–14902. https://doi.org/10.1016/j.ijhydene.2013.09.046
Andreatta F, Terryn H, de Wit JHW (2004) Corrosion behaviour of different tempers of AA7075 aluminium alloy. Electrochimica Acta 49(17):2851–2862. https://doi.org/10.1016/j.electacta.2004.01.046
Venugopal V, Pai S, Olivetti E (2022) MatKG: the largest knowledge graph in materials science–entities, relations, and link prediction through graph representation learning. ar**v:2210.17340
Lewis P, Perez E, Piktus A, Petroni F, Karpukhin V, Goyal N et al (2020) Retrieval-augmented generation for knowledge-intensive NLP tasks. Adv Neural Inf Process Syst 33:9459–9474
Acknowledgements
The authors gratefully acknowledge the support from Novelis and NSF (grant CBET-2243914). We express our gratitude to Mrigi Munjal and Thorben Prein for providing a source of inspiration for the approach we used as well as important code snippets.
Funding
'Open Access funding provided by the MIT Libraries'.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Montanelli, L., Venugopal, V., Olivetti, E.A. et al. High-Throughput Extraction of Phase–Property Relationships from Literature Using Natural Language Processing and Large Language Models. Integr Mater Manuf Innov 13, 396–405 (2024). https://doi.org/10.1007/s40192-024-00344-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40192-024-00344-8