
Abstract
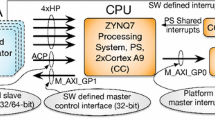
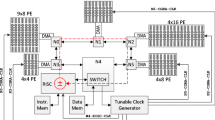
This article describes the implementation of a dynamic scheduler for loading distribution between a hardware accelerator RTL and a CPU software task. The basic composition of a **linx-Zynq SoC device is a processing system (PS), coupled with FPGA programmable logic (PL). The two sections are connected via a number of Advanced eXtensible Interfaces. Hardware accelerators are mechanisms whereby different software algorithms are implemented register transfer logic (RTL) in the PL module. These accelerators determine an increased processing speed. In this article, we present a dynamic scheduler used for distribution of the load between the host processor and the RTL accelerator. There are situations in which even with increased processing speed of the accelerator, it cannot cope with the flow of data coming from memory system (shared memory). Therefore, it is necessary for this accelerator to be “aided” by a software module running in a CPU in the PS section. The article describes a scheduler that checks whether a hardware module for data processing meets the requirement of Hard Real Time (data are processed within a well-defined time frame), and in case it does not, it activates a software thread running on a CPU to support the hardware thread (out of the whole amount of data to be processed by the RTL thread, some of it is processed by the SW thread. Thus, the RTL thread will have less data to process). The scheduler activates the SW thread only when the system has to respond in real time and the amount of data cannot be processed within a certain time. Thus, the scheduler detects the need to activate the software thread that “helps” the hardware thread to process the data. The scheduler self-adjusts so that it executes a number of instructions in the software thread at all times, without introducing delays in running the RTL thread which is much faster. For this project PYNQ Z2 board, Vivado 2018.3 and Jupyter Notebook tools have been used.














Similar content being viewed by others

References
Nunez-Yanez J, Amiri S, Hosseinabady M, Rodríguez A, Asenjo R, Navarro A, Suarez D, Gran R (2018) Simultaneous multiprocessing in a software-defined heterogeneous FPGA. J Supercomput 71:1–18
Arcas-Abella O et al (2014) An empirical evaluation of high-level synthesis languages and tools for database acceleration. In: FPL’14, pp 1–8
Xeon+FPGA platform for the data center. www.ece.cmu.edu/~calcm/carl/lib/exe/fetch.php?media=carl15-gupta.pdf. Accessed 05 Mar 2018
Putnam A et al (2014) A reconfigurable fabric for accelerating large-scale datacenter services. In: International Symposium on Computer Architecture, ISCA’14, pp 13–24
Enabling coherent FPGA acceleration. www.openpowerfoundation.org/wp-content/uploads/2015/03/Cantle_OPFS2015_Nallatech_031315_final.pdf. Accessed 05 Mar 2018
Auerbach J et al (2012) A compiler and runtime for heterogeneous computing. In: DAC’12, pp 271–276
Meng P, Jacobsen M, Kastner R (2012) FPGA-GPU-CPU heterogeneous architecture for real-time cardiac physiological optical map**. In: FPT’12, pp 37–42
Prongnuch S, Wiangtong T (2014) Heterogeneous computing platform for data processing. In: ISPACS’16, pp 1–4
Thoman P, Dichev K, Heller T, Iakymchuk R, Aguilar X, Hasanov K, Gschwandtner P, Lemarinier P, Markidis S, Jordan H, Fahringer T, Katrinis K, Laure E, Nikolopoulos DS (2018) A taxonomy of task-based parallel programming technologies for high-performance computing. J Supercomput 74:1422–1434
Danne K, Platzner M (2005) Periodic real-time scheduling for FPGA computers. In: 3rd International Workshop on Intelligent Solutions in Embedded Systems (WISES’05), pp 117–127
Steiger C, Walder H, Platzner M (2003) Heuristics for online scheduling real-time tasks to partially reconfigurable devices. In: Proceedings of the International Conference on Field Programmable Logicand Applications, pp 575–584
Zhou X, Wang Y, Huang X, Peng C (2007) Fast on-line task placement and scheduling on reconfigurable devices. In: Proceedings of the International Conference on Field Programmable Logic and Applications (FPL’07), pp 132–138
Lu Y, Marconi T, Bertels K, Gaydadjiev G (2009) Online task scheduling for the FPGA-based partially reconfigurable systems. In: Proceedings of the International Workshop on Reconfigurable Computing: Architectures, Tools and Applications, pp 216–230
Marconi T, Lu Y, Bertels K, Gaydadjiev G (2010) 3D compaction: a novel blocking-aware algorithm for online hardware task scheduling and placement on 2D partially reconfigurable devices. In: Proceedings of the International Symposium on Applied Reconfigurable Computing, pp 194–206
Lu Y, Marconi T, Bertels K, Gaydadjiev G (2010) A communication aware online task scheduling algorithm for FPGA-based partially reconfigurable systems. In: Proceedings of the 18th IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM’10), pp 65–68
Ghringer D, Hubner M, Nguepi Zeutebouo E, Becker J (2011) Operating system for runtime reconfigurable multiprocessor systems. Int J Reconfig Comput 2011:1–16
Redaelli F, Santambrogio MD, Memik SO (2008) An ILP formulation for the task graph scheduling problem tailored to bi-dimensional reconfigurable architectures. In: Proceedings of the International Conference on Reconfigurable Computing and fPGAs (ReConFig’08), pp 97–102
Iturbe X, Benkrid K, Hong C, Ebrahim A, Arslan T, Martinez I (2013) Runtime scheduling, allocation, and execution of real-time hardware tasks onto **linx FPGAs subject to fault occurrence. Int J Reconfig Comput 2013:1–32
Digilent, PYNQ-Z1 Board Reference Manual, Revised April 13, 2017
Crockett LH, Northcote D, Ramsay C, Robinson FD, Stewart RW (2019) Exploring Zynq\({\textregistered }\) MPSoC With PYNQ and machine learning applications, strathclyde academic media, Department of Electronic and Electronic and Electrical Engineering University of Strathclyde Glasgow, Scotland, UK
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Tănase, C.A. Dynamic scheduler implementation used for load distribution between hardware accelerators (RTL) and software tasks (CPU) in heterogeneous systems. J Supercomput 76, 10122–10139 (2020). https://doi.org/10.1007/s11227-020-03242-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-020-03242-w