
Abstract
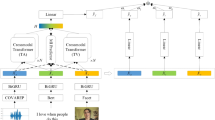
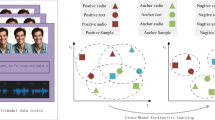
The sentiment of human language is usually reflected through multimodal forms such as natural language, facial expression, and voice intonation. However, the previous research methods uniformly treated different modalities of time series alignment and ignored the missing modal information fragments. The main challenge is the partial absence of multimodal information. In this work, the integrating consistency and difference networks(ICDN) is firstly proposed to model modalities interaction through map** and generalization learning, which includes a special cross-modal Transformer designed to map other modalities to the target modality. Then, the unimodal sentiment labels are obtained through self-supervision to guide the final sentiment analysis. Compared with other popular multimodal sentiment analysis methods, we obtain better sentiment classification results on CMU-MOSI and CMU-MOSEI benchmark datasets.








Similar content being viewed by others

Change history
10 July 2023
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s10489-023-04869-x
References
Gibson KR, Ingold TE (1993) Tools, language and cognition in human evolution. In: Revised versions of the chapters in this volume were presented at the symposium,” Tools, language and intelligence: Evolutionary implications,” held in Cascais. Cambridge University Press, Portugal
Zadeh A, Chen M, Poria S, Cambria E, Morency L-P (2017) Tensor fusion network for multimodal sentiment analysis. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp 1103–1114
Zadeh A, Liang PP, Mazumder N, Poria S, Cambria E, Morency L-P (2018) Memory fusion network for multi-view sequential learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 32
Liu Z, Shen Y, Lakshminarasimhan VB, Liang PP, Zadeh AB, Morency L-P (2018) Efficient low-rank multimodal fusion with modality-specific factors. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp 2247–2256
Mai S, Hu H, ** real-time streaming transformer transducer for speech recognition on large-scale dataset. In: ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, pp 5904–5908
Dong L, Xu S, Xu B (2018) Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, pp 5884–5888
Gulati A, Qin J, Chiu C-C, Parmar N, Zhang Y, Yu J, Han W, Wang S, Zhang Z, Wu Y et al (2020) Conformer: Convolution-augmented transformer for speech recognition. ar**v:2005.08100
Tsai Y-HH, Bai S, Liang PP, Kolter JZ, Morency L-P, Salakhutdinov R (2019) Multimodal transformer for unaligned multimodal language sequences. In: Proceedings of the conference. Association for Computational Linguistics. Meeting, vol 2019. NIH Public Access, p 6558
Cheng J, Fostiropoulos I, Boehm B, Soleymani M (2021) Multimodal phased transformer for sentiment analysis. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp 2447–2458
Liu W, Mei T, Zhang Y, Che C, Luo J (2015) Multi-task deep visual-semantic embedding for video thumbnail selection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3707–3715
Zhang W, Li R, Zeng T, Sun Q, Kumar S, Ye J, Ji S (2015) Deep model based transfer and multi-task learning for biological image analysis. In: 21st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2015. Association for Computing Machinery, pp 1475–1484
Akhtar MS, Chauhan D, Ghosal D, Poria S, Ekbal A, Bhattacharyya P (2019) Multi-task learning for multi-modal emotion recognition and sentiment analysis. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp 370– 379
Yu W, Xu H, Meng F, Zhu Y, Ma Y, Wu J, Zou J, Yang K (2020) Ch-sims: A chinese multimodal sentiment analysis dataset with fine-grained annotation of modality. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp 3718–3727
Ju X, Zhang D, **ao R, Li J, Li S, Zhang M, Zhou G (2021) Joint multi-modal aspect-sentiment analysis with auxiliary cross-modal relation detection. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp 4395–4405
Zhang B, Yu F, Gao Y, Ren T, Wu G (2021) Joint learning for relationship and interaction analysis in video with multimodal feature fusion. In: Proceedings of the 29th ACM International Conference on Multimedia, pp 4848–4852
Pham H, Liang PP, Manzini T, Morency L-P, Póczos B (2019) Found in translation: Learning robust joint representations by cyclic translations between modalities. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 33, pp 6892–6899
Pennington J, Socher R, Manning CD (2014) Glove: Global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp 1532–1543
Degottex G, Kane J, Drugman T, Raitio T, Scherer S (2014) Covarep–a collaborative voice analysis repository for speech technologies. In: 2014 ieee international conference on acoustics, speech and signal processing (icassp). IEEE, pp 960–964
Kingma DP, Ba J (2015) Adam: A method for stochastic optimization. In: ICLR (Poster)
Acknowledgements
This work was supported in part by the National Social Science Foundation under Award 19BYY076, in part Key R & D project of Shandong Province 2019JZZY010129, and in part by the Shandong Provincial Social Science Planning Project under Award 19BJCJ51, Award 18CXWJ01, and Award 18BJYJ04.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of Interests
The authors declare that there is no conflict of interests with anybody or any institution regarding the publication of this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s10489-023-04869-x"
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, Q., Shi, L., Liu, P. et al. RETRACTED ARTICLE: ICDN: integrating consistency and difference networks by transformer for multimodal sentiment analysis. Appl Intell 53, 16332–16345 (2023). https://doi.org/10.1007/s10489-022-03343-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-022-03343-4