
Abstract
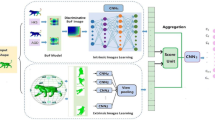
It is important to extract both global and local features for view-based 3D shape classification. Therefore, we propose a 3D shape classification method based on global and local features extraction with collaborative learning. This method consists of a patch-level transformer sub-network (PTS) and a view-level transformer sub-network (VTS). In the PTS, a single view is divided into multiple patches. And a multi-layer transformer encoder is employed to accurately highlight discriminative patches and capture correlations among patches in a view, which can efficiently filter out the meaningless information and enhance meaningful information. The PTS can aggregate patch features into a 3D shape representation with rich local details. In the VTS, a multi-layer transformer encoder is employed to assign different attention to each view and obtain the contextual relationship among views, which can highlight the discriminative views among all the views of the same 3D shape and efficiently aggregate view features into a 3D shape representation. A collaborative loss is applied to encourage the two branches to learn collaboratively and teach each other in training. Experiments on two 3D benchmark datasets show that our proposed method outperforms current methods.










Similar content being viewed by others


Data availability
Previously reported ModelNet10 and ModelNet40 data are used to support this study and are available at http://modelnet.cs.princeton.edu/.
References
Liu, X., Han, Z., Liu, Y.S., et al.: Fine-grained 3D shape classification with hierarchical part-view attention. IEEE Trans. Image Process. 30, 1744–1758 (2021)
Wei, X., Yu, R., Sun, J.: View-gcn: view-based graph convolutional network for 3d shape analysis. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1850–1859 (2020)
Gao, Z., Shao, Y., Guan, W. et al.: A novel patch convolutional neural network for view-based 3D Model Retrieval. Proceedings of the 29th ACM International Conference on Multimedia. 2021: 2699–2707.
Hegde, V., Zadeh, R.: Fusionnet: 3d object classification using multiple data representations. ar**v preprint ar**v:1607.05695 (2016)
Wu, Z., Song, S., Khosla, A. et al.: 3d shapenets: a deep representation for volumetric shapes. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1912–1920 (2015)
Maturana, D., Scherer, S.: Voxnet: a 3d convolutional neural network for real-time object recognition. In: 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp. 922–928 (2015)
Liu, S., Giles, L., Ororbia, A.: Learning a hierarchical latent-variable model of 3d shapes. In: 2018 International Conference on 3D Vision (3DV). IEEE, pp. 542–551 (2018)
Qi, C. R., Su, H., Mo, K. et al.: Pointnet: deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 652–660 (2017)
Qi, C. R., Yi, L., Su, H. et al.: PointNet++ deep hierarchical feature learning on point sets in a metric space. In: Proceedings of the 31st international conference on neural information processing systems. pp. 5105–5114 (2017)
Li, J., Chen, B. M., Lee, G. H.: So-net: self-organizing network for point cloud analysis. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 9397–9406 (2018)
Klokov, R., Lempitsky, V.: Escape from cells: deep kd-networks for the recognition of 3d point cloud models. In: Proceedings of the IEEE international conference on computer vision. pp. 863–872 (2017)
Wang, Y., Sun, Y., Liu, Z., et al.: Dynamic graph cnn for learning on point clouds. Acm Trans. Graph (tog) 38(5), 1–12 (2019)
Liu, Y., Fan, B., **ang, S. et al.: Relation-shape convolutional neural network for point cloud analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8895–8904 (2019)
Su, H., Maji, S., Kalogerakis, E. et al.: Multi-view convolutional neural networks for 3d shape recognition. In: Proceedings of the IEEE international conference on computer vision. pp. 945–953 (2015)
Feng, Y., Zhang, Z., Zhao, X. et al.: Gvcnn: Group-view convolutional neural networks for 3d shape recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 264–272 (2018)
Sun, K., Zhang, J., Liu, J., et al.: DRCNN: dynamic routing convolutional neural network for multi-view 3D object recognition. IEEE Trans. Image Process. 30, 868–877 (2020)
**g, B., Qing, L., Wei, F.: 3D model classification and retrieval based on CNN voting scheme. J. Comput.-Aided Des. Comput. Graph. 31(2), 303–314 (2019)
Ding, B., Tang, L., He, Y. J.: An efficient 3D model retrieval method based on convolutional neural network. Complexity, pp. 1–14 (2020)
Ding, B., Tang, L., Gao, Z., et al.: 3D shape classification using a single view. IEEE Access 8, 200812–200822 (2020)
Liu, Z., Zhang, Y., Gao, J., et al.: VFMVAC: view-filtering-based multi-view aggregating convolution for 3D shape recognition and retrieval. Pattern Recogn. 129, 108774 (2022)
Liang, Q., Li, Q., Zhang, L., et al.: MHFP: multi-view based hierarchical fusion pooling method for 3D shape recognition. Pattern Recogn. Lett. 150, 214–220 (2021)
Liu, A.A., Guo, F.B., Zhou, H.Y., et al.: Semantic and context information fusion network for view-based 3D model classification and retrieval. IEEE Access 8, 155939–155950 (2020)
Gao, Z., Xue, H., Wan, S.: Multiple discrimination and pairwise CNN for view-based 3D object retrieval. Neural Netw. 125, 290–302 (2020)
Kanezaki, A., Matsushita, Y., Nishida, Y.: Rotationnet: Joint object categorization and pose estimation using multiviews from unsupervised viewpoints. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5010–5019 (2018)
Han, Z., Lu, H., Liu, Z., et al.: 3D2SeqViews: aggregating sequential views for 3D global feature learning by CNN with hierarchical attention aggregation. IEEE Trans. Image Process. 28(8), 3986–3999 (2019)
He, X., Huang, T., Bai, S. et al.: View n-gram network for 3d object retrieval. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7515–7524 (2019)
Han, Z., Shang, M., Liu, Z., et al.: SeqViews2SeqLabels: learning 3D global features via aggregating sequential views by RNN with attention. IEEE Trans. Image Process. 28(2), 658–672 (2018)
Liu, A.A., Zhou, H.Y., Li, M.J., et al.: 3D model retrieval based on multi-view attentional convolutional neural network. Multimed. Tools Appl. 79(7), 4699–4711 (2020)
Liu, A.A., Zhou, H., Nie, W., et al.: Hierarchical multi-view context modelling for 3D object classification and retrieval. Inf. Sci. 547, 984–995 (2021)
Liang, Q., Wang, Y., Nie, W., et al.: MVCLN: multi-view convolutional LSTM network for cross-media 3D shape recognition. IEEE Access 8, 139792–139802 (2020)
Han, Z., Liu, X., Liu, Y. S. et al.: Parts4Feature: learning 3D global features from generally semantic parts in multiple views. In: Twenty-eighth international joint conference on artificial intelligence (IJCAI 2019) (2019)
Yu, R., Sun, J., Li, H.: Second-order spectral transform block for 3D shape classification and retrieval. IEEE Trans. Image Process. 29, 4530–4543 (2020)
Yu, T., Meng, J., Yuan, J.: Multi-view harmonized bilinear network for 3d object recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 186–194 (2018)
Zhao, H., Jiang, L., Jia, J., Torr, P. H. and Koltun, V.: Point transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 16259–16268 (2021)
Gao, Y., Liu, X., Li, J., Fang, Z., Jiang, X., Huq, K.M.S.: Lft-net: local feature transformer network for point clouds analysis. IEEE Trans. Intell. Transp. Syst. (2022). https://doi.org/10.1109/TITS.2022.3140355
Pan, X., **a, Z., Song, S., Li, L. E. and Huang, G.:. 3d object detection with pointformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition,pp. 7463–7472 (2021)
Liu, Z., Lin, Y., Cao, Y. et al.: Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
He, J., Chen, J.N., Liu, S., et al.: Transfg: a transformer architecture for fine-grained recognition. Proc AAAI Conf Artif Intell 36(1), 852–860 (2022)
Hassani, A., Walton, S., Shah, N. et al.: Esca** the big data paradigm with compact transformers. ar**v preprint ar**v:2104.05704, (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A. et al.: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In: International conference on learning representations (2020)
Tarvainen, A., Valpola, H.: Mean teachers are better role models: weight-averaged consistency targets improve semi-supervised deep learning results. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 1195–1204 (2017)
Ge, Y., Chen, D., Li, H.: Mutual mean-teaching: pseudo label refinery for unsupervised domain adaptation on person re-identification. In: International Conference on Learning Representations (2019)
Chen, S., Hong, Z., Hou, W., et al.: TransZero++: cross attribute-guided transformer for zero-shot learning. IEEE Trans. Pattern Anal. Mach. Intell. 01, 1–17 (2022)
Acknowledgements
This paper is supported by the National Natural Science Foundation of China (No.61673142) and the Natural Science Foundation of Hei LongJiang Province of China (No.LH2022F029).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ding, B., Zhang, L., He, Y. et al. 3D shape classification based on global and local features extraction with collaborative learning. Vis Comput 40, 4539–4551 (2024). https://doi.org/10.1007/s00371-023-03098-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-023-03098-0